
As you know MS decided to depracate another tool “Export to Data Lake” and use “Synapse Link” instead.
We need data for reporting/integrations and struggling with data entities for several years. Yes , yes they have other purposes as well but still Export to data lake was real solution here. Now MS moved one step ahead. There is more to learn for us. You need to read instructions in between sections carefully. Especially you are doing this setup for the first time.
Detail can be found here :
Azure Synapse Link – Power Apps | Microsoft Learn
If you decide to use Synapse Link with Dataverse setting up with data storage is enough.
If you need to use Synapse Link with D365FO , first things first, your environment needs to be
10.0.34 (PU58) cumulative update 7.0.6931.171 or later.
10.0.35 (PU59) cumulative update 7.0.6972.149 or later.
10.0.36 (PU60) cumulative update 7.0.7036.78 or later.
10.0.37 (PU61) cumulative update 7.0.7068.39 or later.
Otherwise you need to wait until next upgrade.
Setup is pretty straightforward.
You can do D365FO setup following instructions below:
You don’t see Azure Synapse Link in the Power Apps site menu by default.
Just follow the URL :
https://make.powerapps.com/environments/<environment ID>/exporttodatalake?athena.enableFnOTables=true
You can pin afterwards.
I assume you already have Azure storage and Azure synapse workspace. If not , follow the instructions.
Now, hints are not clear on “new link” screen.
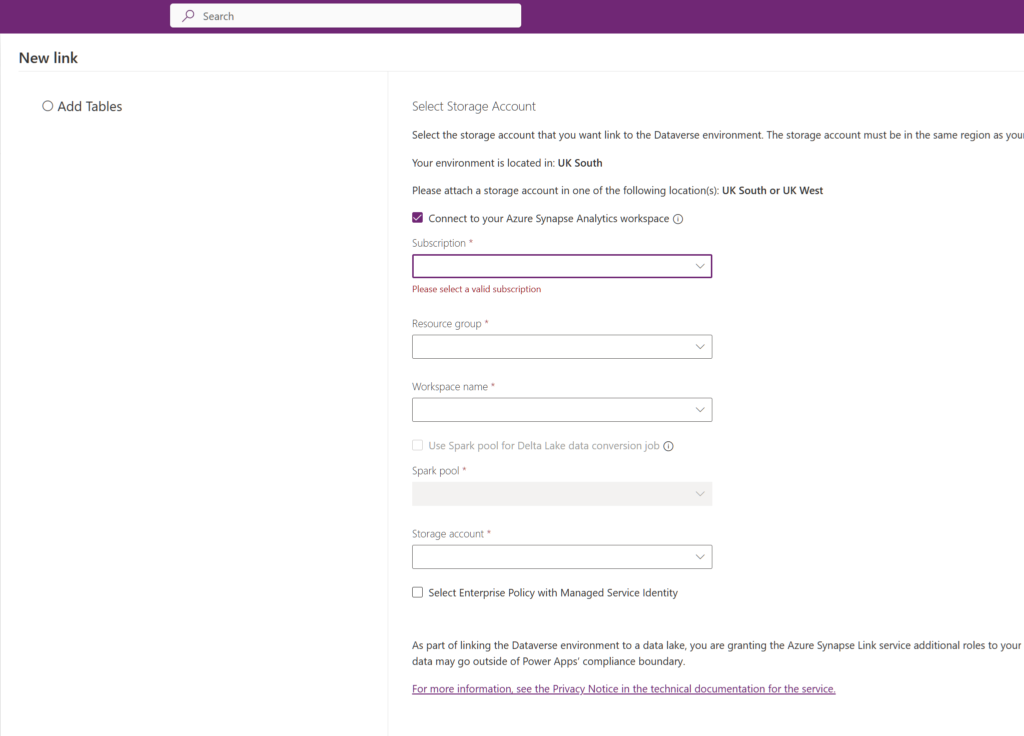
If you select connect Azure synapse workspace then you see tables in workspace table list. Otherwise you can see files at the linked section as a csv.
Not sure if it is a rule but I had to crate Azure synapse workspace and storage in same resource group. Otherwise I couldnt select.
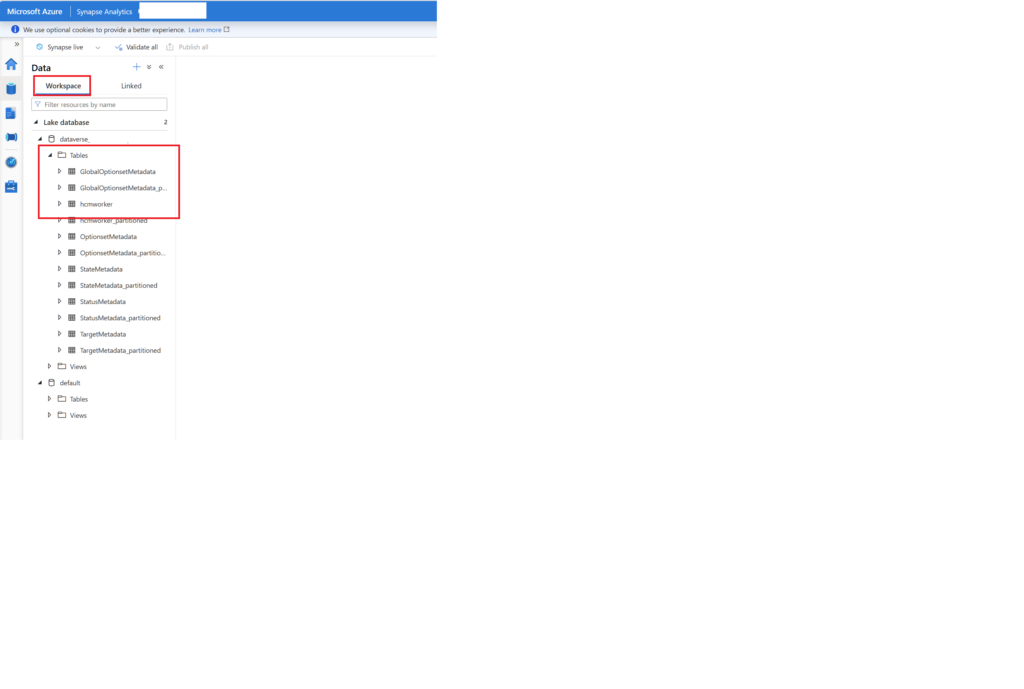
For D365FO you need to create a Apache Spark Pool in Azure Synapse workspace and select the option. Its version should be 3.1 . Otherwise won’t show up in the list . (May be they change this in the future)
If you don’t select this option it won’t link tables to workspace. you will see as csv files only.
One more little note, by using Apache spark pool, azure synapse creates one csv file and manages updates. if you go for sql pool then it creates csv per update. Looks like you need to setup CDM.
Good luck!